前回の「KerasとTensorflowを使ったアニメキャラ予測」では,元データ686枚でキルミーベイベーのキャラクターを学習させました。
686枚でも思っていた以上に精度よく予測できたけれど,出来ることならもう少しデータ数を増やしたい。でも手作業で大量のデータ集めをするのは面倒臭い……
...というわけで,指定したフォルダ内の動画ファイルを読み込んでキャラごとの顔画像を自動分類するプログラムを書きました!複数動画ファイルを一度に処理できます!
参考にしたサイト
OpenCVのカスケードファイルは, id:ultraist様の作成したものを使わせていただきました。
保存先のディレクトリとか
<C:>
| - <samplepy>
| | - <kill_me_data_converter.py>
| | - <kill_me_learning.py>
| | - <kill_me_classification.py>
|
| - <Machine_Learning_data>
| | - <kill_me_baby_data>
| | | - <yasuna>
| | | - <sonya>
| | | - <agiri>
| | | - <botsu>
| | | - <others>
| | | - <yasuna&sonya>
| |
| | - <kill_me_baby_data_create>
| | |- <yasuna>
| | |- <sonya>
| | |- <agiri>
| | |- <botsu>
| | |- <others>
| | |- <yasna&sonya>
| |
| | - <kill_me_video>
以降を新しく追加しました。それ以外は前回と一緒です。
では早速。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from PIL import Image
import sys, os, glob
import numpy as np
import shutil
import h5py
import cv2
# 画像の名前重複防止
img_name = "kill_me_" # 例)1kill_me_1.png
# 検出した画像の保存先
save_dir = 'C:/Machine_Learning_data/kill_me_baby_data_create'
categories = ['yasuna','sonya','agiri','botsu','others','yasuna&sonya']
# 学習済みモデル
hdf5_file = 'C:/Machine_Learning_data/kill_me_baby_data/kill_me-model.hdf5'
# 動画のあるディレクトリ
video_dir = 'C:/Machine_Learning_data/kill_me_video'
# カスケードファイル
cascade_file_1 = 'C:/Machine_Learning_data/lbpcascade_animeface.xml'
"""
-------------------使い方----------------------------
save_dir : 保存ディレクトリ
video_file: 読み込む動画のパス
cascade_file:OpenCVのカスケードファイル
動画内で検出したオブジェクトを切抜いて保存します。
-----------------------------------------------------
"""
def face_detecsion(save_dir, video_dir, cascade_file_1, img_name):
# ディレクトリ内の動画ファイルを列挙
video_files = glob.glob(video_dir+"/*.mp4")
cascade_1 = cv2.CascadeClassifier(cascade_file_1)
total_num = 0
# 動画ごとのループ
for i, f in enumerate(video_files):
# 動画ファイル読み込み
video = cv2.VideoCapture(f)
# 初期値
number_1 = 0
frame_num = 0
image_min = 64 # 検出する画像の最小サイズ
while(video.isOpened()): # 動画が開かれている間はループ
flag, frame = video.read()
frame_num += 1
# 30フレームごとに実行
if frame_num % 30 == 0:
# グレイスケール化
image_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# カスケードファイルを用いて検出
faces_list = cascade_1.detectMultiScale(image_gray,
scaleFactor = 1.13,
minNeighbors = 2,
minSize = (image_min, image_min))
# 顔があれば切り抜いて保存する
if len(faces_list) > 0:
for rect in faces_list:
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
# 顔を切り抜く
face_img = frame[y:y + h, x:x + w]
# save_dirに連番で保存(iは57行目の変数.名前重複防止)
cv2.imwrite(save_dir + "/" + str(number_1) + img_name + str(i)) + ".png", face_img)
number_1 += 1
total_num += 1
# 切り抜いた画像総数
print("\r", "detection & saved:", total_num,end="")
# 10[ms]だけキーボード入力を受け付ける
if cv2.waitKey(10) & 0xff == ord('q'):
break
# 終了処理
print("\n")
print("Ok!", total_num, "images are succcessfully saved.")
print("Save directry :", save_dir)
video.release()
cv2.destroyAllWindows()
"""
-------------------------使い方----------------------------
save_dir:画像が保存してあるファイル
categories:分類カテゴリ
hdf5_file:Kerasで構築したCNNモデルの学習済データ
指定したディレクトリの画像を読み込んで予測,分類して保存する.
保存先はsave_dir以下の各分類ディレクトリ
-----------------------------------------------------------
"""
def image_pre(save_dir, categories, hdf5_file):
nb_classes = len(categories)
image_size = 64
pixels = image_size * image_size
total_num = 0
# 各カテゴリの枚数を数える変数と初期値
num_count = []
for i, cat in enumerate(categories):
num_cat = cat + "_num"
num_count.append(num_cat) # num_count = [yasuna_num, sonya_num, ...]
num_count[i] = 0
del num_cat
# save_dir内の「.png」ファイルだけを列挙
img_files = glob.glob(save_dir+"/*.png")
print("画像総数:", len(img_files),"枚")
for i, f in enumerate(img_files):
X = []
files = []
with open(f, "r") as img :
img = Image.open(f)
img = img.convert("RGB")
img = img.resize((image_size, image_size))
data = np.asarray(img)
X.append(data)
files.append(f)
X = np.array(X)
# CNNのモデルを構築
model = Sequential()
model.add(Conv2D(32, (3, 3),
padding = 'same',
input_shape = X.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes)) # 出力データのカテゴリー数を指定
model.add(Activation('softmax'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 学習済みモデルをロード
model.load_weights(hdf5_file)
# 読み込んだ画像を予測
pre = model.predict(X) # 予測値を格納したNmupy配列.
for i, p in enumerate(pre):
y = p.argmax() # 最も予測確立の高いカテゴリ
num_count[y] += 1 # 枚数計算
# ディレクトリ移動
img_save_dir = save_dir + "/" + categories[y]
shutil.move(f, img_save_dir) # shutil.move("元", "移動先")
total_num += 1
# 進捗表示
percentage = (total_num * 100) // len(img_files)
print("\r","progress:", percentage,"%",end="")
# 処理内訳
print("\n","-" * 30,"Processing-Exit","-" * 30)
print("画像総数:", len(img_files),"枚")
for i in range(len(categories)):
cat_num = categories[i] + "_num"
print("|" ,categories[i],":",num_count[i],"枚", end=" ")
# 実行
face_detection(save_dir, video_dir, cascade_file, img_name)
image_pre(save_dir, categories, hdf5_file)
2つの処理を一つにまとめたのでやたらと長くなってしまいました。細かい説明はコメントに書いてあるので,そちらをご覧ください。
処理の流れとか。
変数てんこ盛りでごちゃごちゃしてますが,大まかな処理の流れは次の通りです。
- 動画を読み込む
- 指定したフレーム数ごとにスキャン
- カスケードファイルで検出した部分を切抜き & 保存.
- 学習済みモデルを使用して予測 & ディレクトリ移動
1~3が関数内での処理で,4が内での処理です。
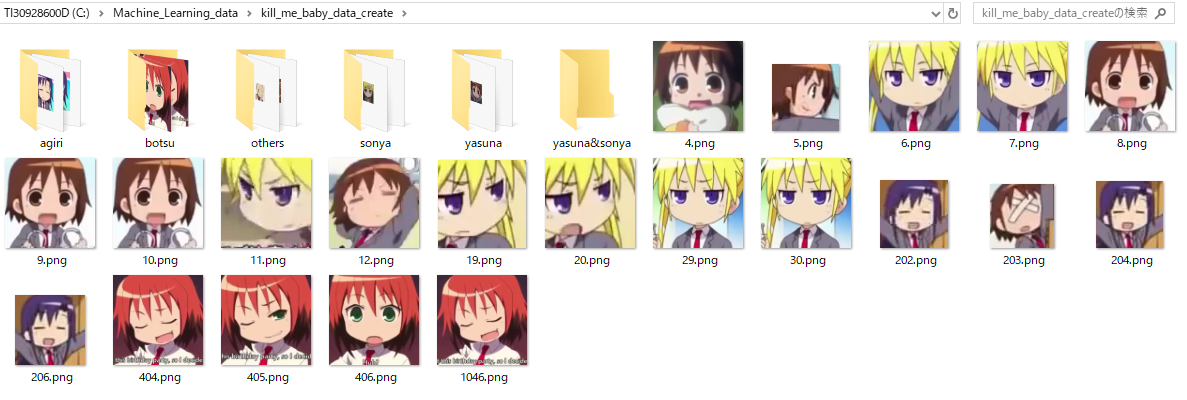 実際はもっと沢山の画像が生成されますが,を実行するとこんな感じに切抜かれて保存されます。
実際はもっと沢山の画像が生成されますが,を実行するとこんな感じに切抜かれて保存されます。
使用させていただいたカスケードファイルの精度がとても高く,キャラの顔部分だけを正確に検出して切抜いてくれました。





(yasuna&sonyaは画像無しでした。)
ところどころ誤分類された画像もありますが,元データ686枚でここまで分類できれば上出来ではないでしょうか。
メモリ食いすぎ...
face_detectoin()での処理はとても軽いので小さいノートパソコンでも余裕で動きますが,image_pre()を実行するとメモリバカ食いします。タスクマネージャーでメモリの使用状況を見ていると,画像を分類するごとに少しずつ消費していて,恐らくですがメモリが大きければ大きいだけ上限無く増えます。
手動GC(Garbage Collection)も試してみましたが一向に改善しません…。最初は,ディレクトリ移動の部分でデータが蓄積してメモリ消費してるのかなと思い,ファイルの移動処理を無くして実行してみたのですがメモリ消費量は変化しませんでした。
あとはCNNモデルを弄るしかないんですけど,予測するだけでそこまでメモリ消費するものなんでょうか。
別にパソコンが壊れるとかそういうことはないので,気にせずにこのまま使うのもアリですが,原因がわかる方いらっしゃいましたらご教授いただきたく思います。
おまけ
処理時間が長いプログラムを書いたときに進捗が見れたら便利ですよね。
そんなわけで,前回から進捗度合いを表示するようにしてあります。
import time
files = ["a", "b", "c"]
for s, t in enumerate(files):
for i in range(100):
time.sleep(0.05)
print("\r",t,":", i,"%",end="")
print("\n")

プログラム中の「\r」はキャリッジリターンと呼ばれるエスケープシーケンスです。
print関数だけで表示できるのは良いですよね。両端に「\r」と「end=””」を書くのがポイントで,最後に「\n」を書くのは,次に表示する文字を改行して表示されるようにするためです。